
動画視聴数は対数正規分布する
始めに,この記事の要約です.
- 2018年6月11日現在で公開されていた,すみながめの動画76本の再生回数を分析
- 動画の\(\displaystyle 日平均視聴数 = \frac{再生回数}{公開期間}\) が対数正規分布することを発見
- 今回のデータの母数は \(\mu=-0.01, \sigma=0.92\)
- \(\displaystyle 人気 = \log \left( \frac{再生回数}{公開期間}\right)\)として,人気の偏差値を算出
- 76本中6位の再生回数の#57の人気が最も高いことが分かった
すみながめは2018年7月5日現在で79本のInkscapeの使い方動画を掲載しています.これらの動画がどのように視聴され,視聴者が本当に求めている動画チュートリアルはどのようなものであるのか,すみながめでは頻繁に分析を行い制作に反映しています.今回の記事では,2018年6月11日に行われた分析作業の一部を公開します.
今回の分析の趣旨は「人気度の高い動画と低い動画を見分ける境目を決めよう」ということです.特に頻繁に視聴されている動画は人気度が高く,あまり視聴されていない動画にはそれどど需要が無いだろうことが予測できます.需要に確実に答えていくためには,どのようなタイプの動画に需要があり (すなわち人気があり),どのようなタイプの動画に需要が無い (すなわち人気が無い) のかを見極めることが重要です.
視聴回数と日平均視聴回数
まずは単純に,分析当日2018年6月11日までに公開された全76本の動画の視聴回数を調べることから始めました.各動画の視聴回数は下のグラフのようになりました.初期の動画 (#01 – #20) の中に,抜群の視聴回数を誇る動画が6個ほどあり,また2017年10月から2018年2月ごろの期間に公開された動画 (#50 – #65) にも5つほど人気な動画がありそうであることが分かります.
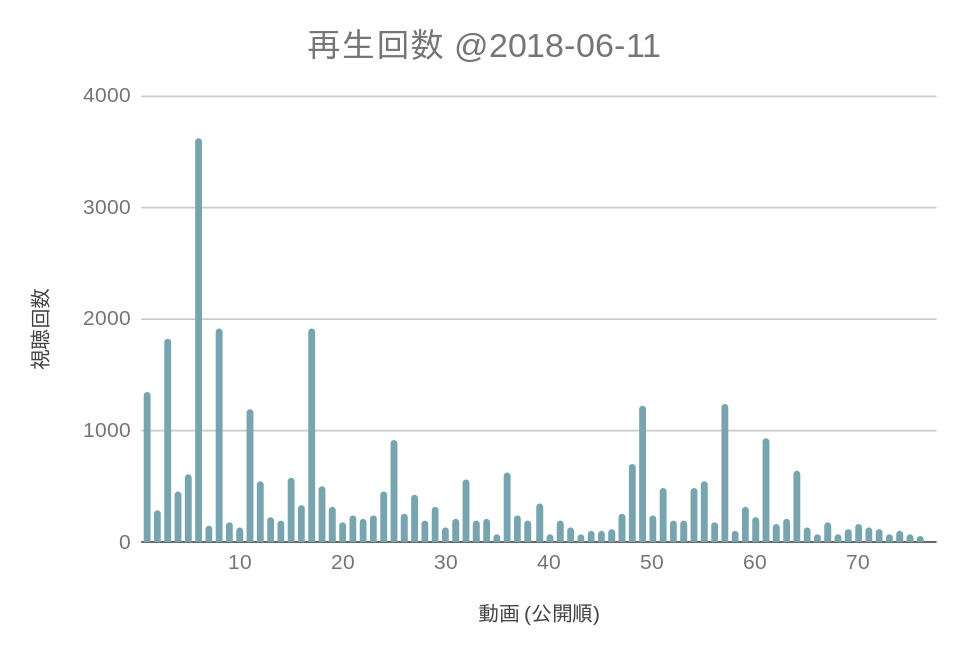
一方で, #01 が公開された2016年4月4日からの分析当日2018年6月11日までの経過日数は799日で,当時最新だった動画 #76 の公開日2018年6月4日までの経過日数7日と比べると約110倍も公開期間に違いがあります.これでは等しく比較できているとは到底思えません.公開されている期間が異なるので,2つの動画の「視聴回数」を比較することに意味が無いのです.
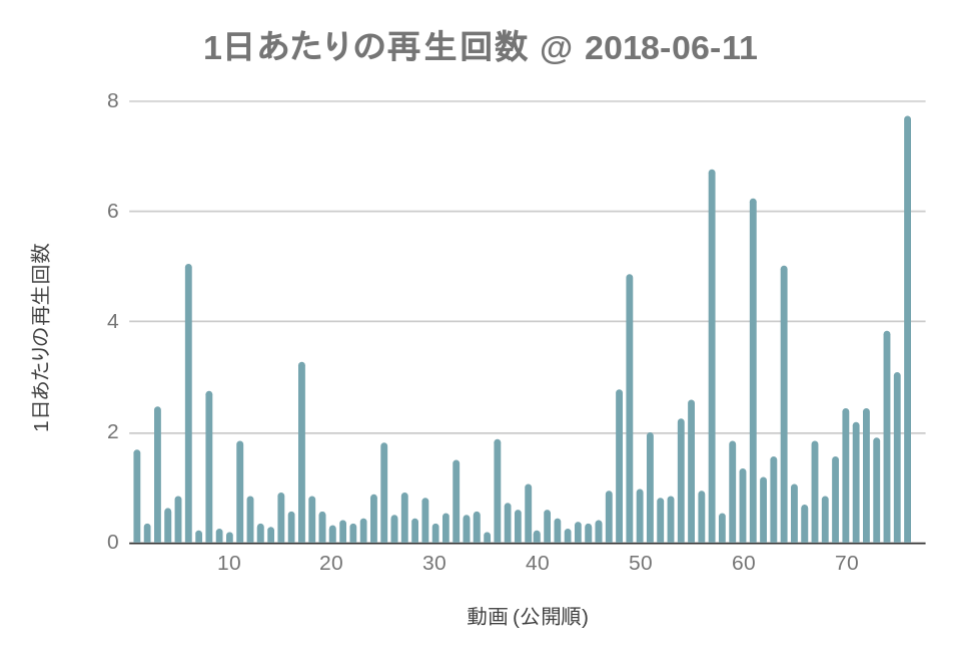
そこで「1日あたりの視聴回数」を算出して,その比較によってど動画が人気なのかを探れないかを検討してみます.このようにして見ると,単純な視聴回数の比較だけでは見えてこなった事実が浮かび上がります.比較的古い動画 (#01 – #45) よりも,比較的新しい動画 (#46- #76) の方が,1日あたりの視聴回数は多そうに見えます.
データの度数分布と正規性検定
さて,これらの中で「特に1日あたりの視聴回数が多い動画」はどれでしょうか?つまり,ある基準を設定して「これよりも日平均視聴回数が多い動画は,特に日平均視聴回数が多いと判定する」と言える「基準」を定めることは出来るでしょうか?見た目で判断することも可能ですが,やはりここは数学に頼りたいところです.直感よりも数値的な分析のほうが信頼できると,初州ういす (著者) は考えるからです.
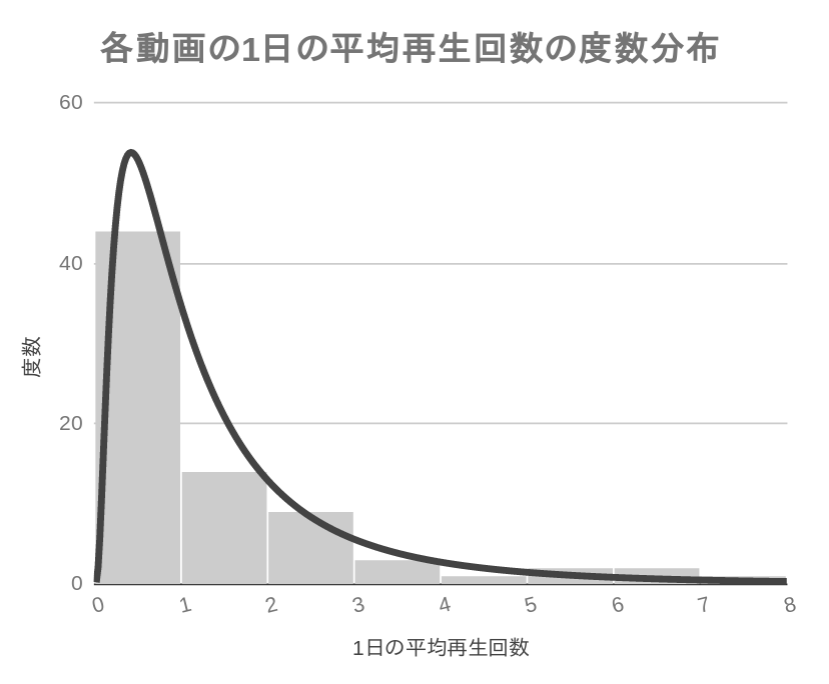
分析のために,先ほどの「1日あたりの視聴回数」のデータの度数分布図 (ヒストグラム) を作成しました.このグラフから,すみながめチャンネルの動画のほとんどは1日に1回も視聴されていないことが分かります.実際に,このデータで1日の平均視聴回数が1回以下の動画の割合は,全体のおよそ58%でした.
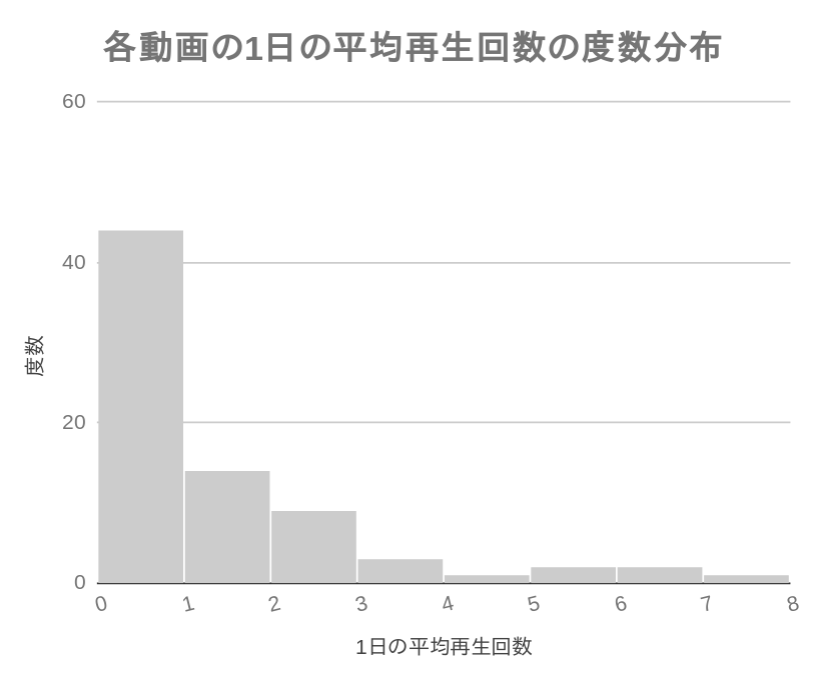
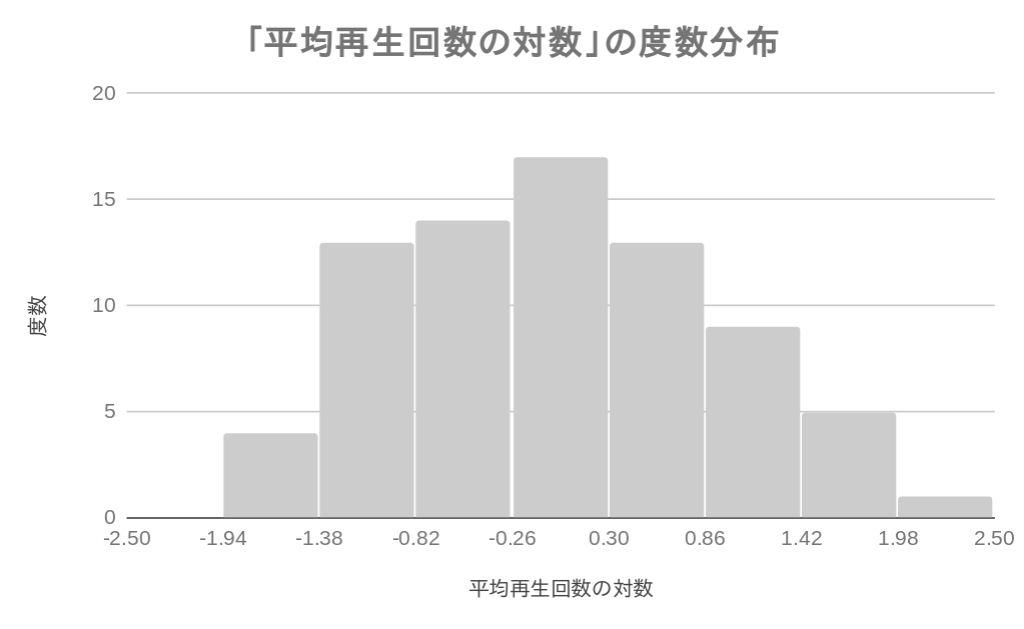
上のグラフを見て,初州ういすは「この分布は対数正規分布に見える」と感じました.この分布が対数正規分布であるかどうかを検定するためには,各数値の対数を取って,その分布が正規分布するかどうかを見れば分かります.下のグラフは参考のために,日平均視聴回数の対数の度数分布を書いたものです.
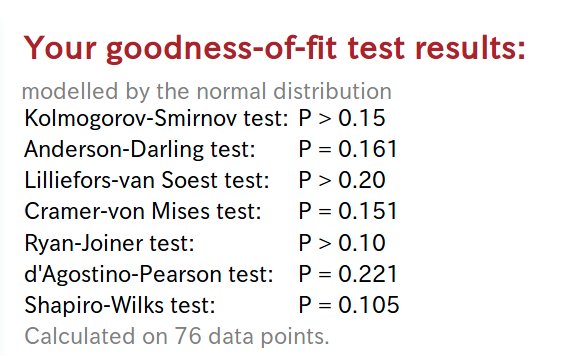
正規性の検定には Goodness-of-fit tests というサイトを使用しました.このサイトはデータを入力するだけで,7つの検定方法でデータの分布の正規性を検定したp値を一覧で出してくれる便利なサービスです.詳細な説明についてはサイトの表示を引用します.
Null hypothesis:
“The data can be modelled according to the normal distribution.”
When the P value is small enough you can conclude that the data set is not following the normal distribution. How much “small enough” is depends on how rigorous you wish to be, but common threshold values for P are 0.05 or 0.01.
The smaller the P value is, the more certain you can be that the data set doesn’t follow the normal distribution.
Warning:
It is not good statistical practice to simultaneously use or report all of the tests above; use only one of the tests, and if possible decide a priori which of them you will use.
有意水準\(\alpha=0.05\)として,今回のデータは7つ全ての検定で\(p>\alpha\)ですから,データ (日平均視聴回数の対数) が正規分布に従うと判断して良さそうです (p値の扱いに関する議論は盛んですが,ここでは従来的なp値の扱いをします…).つまり,元のデータが対数正規分布していると考えて良さそうな根拠がここにあります.
母数と偏差値
すみながめの動画の1日あたりの視聴回数が対数正規分布することが分かれば,分析は簡単です.普通の計算によって,分布の母数を計算できます.以下におよその値を示します.
\(\begin{eqnarray}\mu &=& -0.01\\\sigma&=&0.92 \end{eqnarray}\)
参考までに,この母数に従う対数正規分布と,実データの分布を比べられるグラフを作成してみました.よくフィットしていることが視覚的に確認できまると思います.
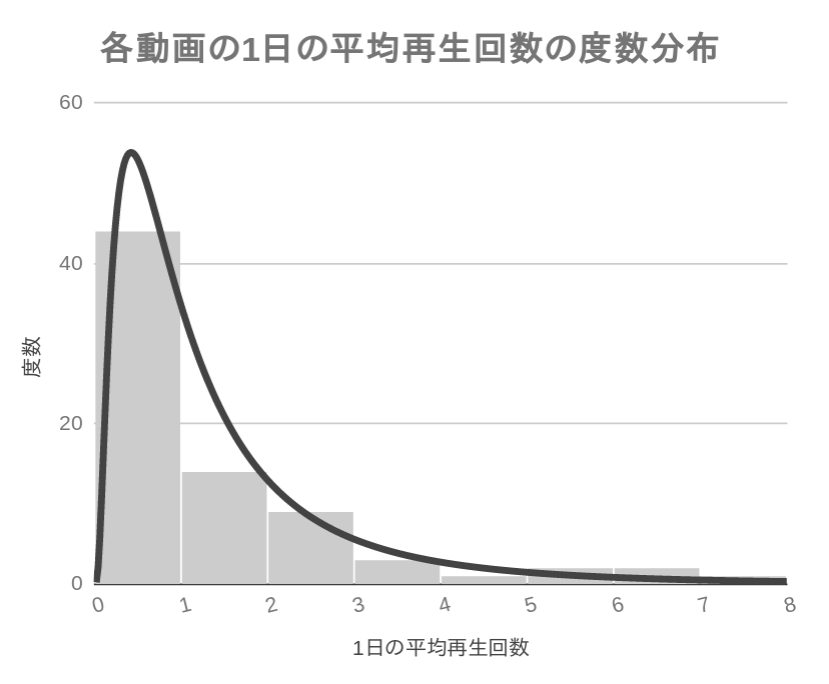
また,上記2つの母数\(\mu,\sigma\)が分かることによって,生データからは見出しづらい「最瀕値」などの重要指標を算出することもできます.上記の\(\mu\sim0\)からもデータの\(中央値\sim1\)なのが頷けますし,すなわち日平均視聴回数が1以下の動画が全体の58%であることとも整合的です.
\(\begin{eqnarray}平均値(期待値)&=&1.5\\中央値&=&0.99\\最瀕値 & = &0.42\end{eqnarray}\)
平均値(期待値)だけは元データから簡単に算出できますが,その値も約1.5であり,(当然ですが) ほとんど誤差がありません.
さて,元データ (日平均視聴回数) の対数を取れば正規分布するということは,そこでの偏差値を簡単に計算できます.\(\mu+\sigma\)の偏差値は60ですから,日平均視聴回数の対数が約0.91よりも大きいデータ (つまり日平均視聴回数が約2.49以上) が,いわゆる「偏差値60以上」と言っていいでしょう.以下に日平均視聴回数の対数が偏差値60以上となった11本の「成績優秀動画」を日平均視聴回数順に列挙します.ただし,#76の成績は7.7視聴/日: 偏差値72.3で1位ですが,公開期間が7日とかなり短い (2番目に短い#75ですら3倍以上の22日間公開されている) こともあり,今回は外れ値として無視しています.
- #57 (6.8視聴/日: 偏差値70.9)
- #61 (6.2視聴/日: 偏差値69.9)
- #06 (5.1視聴/日: 偏差値67.7)
- #64 (5.0視聴/日: 偏差値67.6)
- #49 (4.8視聴/日: 偏差値67.2)
- #74 (3.8視聴/日: 偏差値64.7)
- #17 (3.3視聴/日: 偏差値62.9)
- #75 (3.1視聴/日: 偏差値62.4)
- #48 (2.8視聴/日: 偏差値61.3)
- #08 (2.8視聴/日: 偏差値61.1)
- #55 (2.6視聴/日: 偏差値60.5)
日平均視聴回数を降順に並べれば,#03が#55の次に来ます.しかし#03の偏差値は59.9 (日平均視聴回数2.46) であるため,今回の基準では成績優秀動画には含まれませんでした.
偏差値を考えることは有意味か?
単純に成績上位のN個の動画を「成績優秀動画」とするよりも,これまでの議論のように偏差値を基準に考えることのほうが,一定の客観性があると言えるように聞こえる知れません.しかし,データが正規分布することが既に分かっているので,「偏差値60以上」は単純に「上位約15.9%」を意味するだけです.
#76を除く75本の動画が対象ですから,上位15.9%とはつまり上位11(あるいは12)個の動画を選び出すことと同義です.数学的に客観的な判断と見せかけて,単に「基準をそのように選んだ」ということしか意味しません.その意味では,特に顕著な意味のある結論ではありません.

しかし,このように全てのデータを精緻に観察することは,データ分析において欠かせない態度だと初州ういすは考えます.特に,今回のように「視聴回数」でもなく「1日あたりの平均視聴回数」でもなく「1日あたりの平均視聴回数の対数」を考え,その分布を調べたことによって判明した事実は無意味ではないと思います.
例えば,母数を推定したことで算出された「最瀕値」は面白い指標です.なぜなら最瀕値は母数を明らかにしばければ推定できないもので,つまり生データからは最瀕値を知ることができないからです.すみながめの動画は,最も典型的には1日当り0.42回しか視聴されていないという事実は,次なる対策を検討する貴重な材料になると感じました.それ故に,このような重要な指標を数学的に真摯に算出できたことは,初州ういすにとっては大変意義のあることでした.
“動画視聴数は対数正規分布する” への2件の返信